A Brief History of Computer Languages
Or: a whistle-stop tour through ways people have talked to computers, before we kick off with more in-depth tutorials.
Ada Lovelace wrote the first ever computer program without even having a computer. She wrote out a detailed description of how one would calculate Bernoulli numbers on Babbage’s Analytical Engine (sadly never built). She, and others, also considered punch cards as a means of encoding the instructions to an Engine-like device. For more on this, see LV001 (if you haven’t seen it yet, you can download the full PDF from here: www.linuxvoice.com/download-linux-voice-issue-1-with-audio).
The first computers that were successfully built, in the 1940s, were programmed in machine code, or at best in assembly language, with mnemonics rather than numeric codes. Whilst this lent itself to a high degree of fine-tuning, it was also error-prone and very hard work.
Those early programmers were interested in developing high-level languages; languages that were abstracted from the details of the machine doing the work. This allows a programmer to specify what they want without worrying about the details of memory location, chip instructions, and so on. The first high-level language ever designed was Zuse’s Plankalkül, but as he lacked a functional computer at the time it wasn’t implemented until over 50 years later.
The early 1950s saw several more attempts. Short Code (designed by John Mauchley) was implemented for UNIVAC, and aimed to make mathematical expressions easier to code. However, it was interpreted rather than compiled, so had to be translated every time, running about 50 times slower than assembly. The first compiled language was Autocode, developed at the University of Manchester for the Mark 1. Grace Hopper’s FLOW-MATIC was a couple of years later, and was aimed at business customers who might be uncomfortable with mathematical notation. None of these are still in use today; but their successors, Fortran, Lisp and COBOL, have all survived.
Fortran was created in 1957. It had 32 statements, and was of course stored on punchcards, one card per line of code. Compilers for many different computers were rapidly developed due to its growing popularity, making it arguably the first cross-platform language. Here’s an example (save as hello.f95):
! Hello World program hello print *,”Hello World” end program hello Install the gfortran package, and compile it with f95 -o hello hello.f95, then run it with ./hello.

Fortran code and code compiling/running, again. The ! line is a comment.
Lisp emerged in 1958. The name derives from LISt Processing, and Lisp is heavily list-based (and, famously, involves a lot of brackets). Here’s a Hello World (save as hello.lisp):
(write-line “Hello World”)
Install sbcl (if you want to do much Lisp development you’ll also want to install and set up Slime (the Superior Lisp Interaction Mode for Emacs) and Emacs), and run this with sbcl –script hello.lisp.
COBOL was designed in 1959–1960, by a steering committee, and took a lot of features from FLOW-MATIC. It was intended to be verbose and easy to understand for non-experts, and to be highly flexible for multiple uses. Although it’s often derided, a significant number of large organisations still have COBOL legacy code on mainframes. Here’s a Hello World example (save as hello-cobol):
IDENTIFICATION DIVISION. PROGRAM-ID. HELLO-COBOL. PROCEDURE DIVISION. DISPLAY ‘Hello World!’. STOP RUN.
Install the open-cobol package, compile with cobc -free -x -o hellocobol-exe hello-cobol and execute.
After these first language pioneers, as the 1960s and 1970s progressed, more languages, and more programming theory, began to develop; along with various distinctions and coding structures (some of which overlap with one another).

Our simple COBOL example running in the right-hand window (note syntax error on first compile!).
Array programming
The basic idea of array programming is to apply an operation to a range of values at the same time. So an operation will, instead of adding two single numbers, add two arrays (or vectors, or matrices, or other grouped data, depending on the language and the problem being handled). This is particularly useful for mathematicians, who often want to deal with grouped data like this.
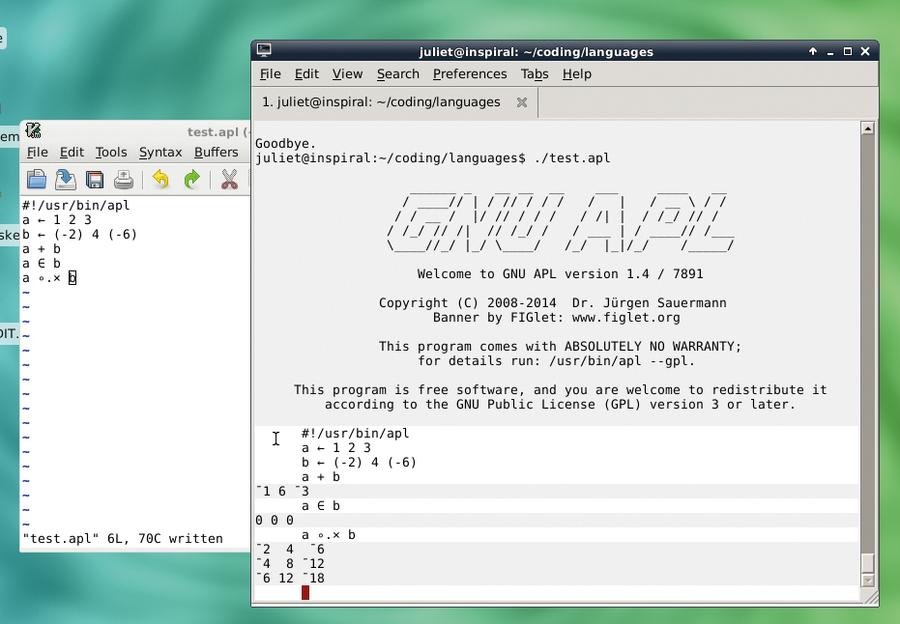
Given that early computing was closely linked with mathematics, it’s not surprising that dealing with arrays was of immediate interest. Fortran had some array handling from the start, but was more multi-purpose, and full array handling wasn’t introduced until Fortran 90. APL (A Programming Language), one of the best-known array programming languages, was developed between 1957 and 1967. It was explicitly intended to provide a language for applied mathematics. It uses a multi-dimensional array as its basic data type, and has special characters to represent specific operations. This makes for code which is concise, but baffling to read for the non-expert. Here’s an example:
#!/usr/bin/apl a ← 1 2 3 b ← (-2) 4 (-6) a + b a Є b a ° . × b
APL uses ← (Unicode leftward arrow) for assignment. a + b simply adds.The Є character (Unicode element of) returns 1 if the element in position n is the same in both a and b, and 0 otherwise. Finally, – . is the outer product operator, which applies a specific operation to all the combinations of the elements of the operands. So here, we multiply (× – not the character x but the Unicode multiplication character) b by each of the elements of a in turn.
Run with ./test.apl, to get the output
-1 6 -3
0 0 0
-2 4 -6
-4 8 -12
-6 12 -18
The supercomputers of the 1960s and 1970s were designed to handle vectors and arrays with particular ease. Other modern array programming languages include J, MATLAB, and S-Lang.
Both Vim (using digraphs) and Emacs (using an appropriate Lisp file and chords) will support APL characters.
Imperative vs declarative programming
Imperative programming involves issuing a series of commands to the computer. At the hardware level, almost all computers operate in an imperative style, with machine code consisting of instructions operating on memory contents. Initially, computer programmers were using machine language, and thus an imperative style; so the first high-level languages (such as Fortran and COBOL) were similar. It does make a certain cognitive sense to write your code as a set of algorithmic steps.
Declarative programming takes a different approach. Instead of telling the computer how to perform a task (what steps to take), it describes what computation should be carried out, and the compiler then translates this into specific steps. Pure declarative programming also avoids “side effects” (functions that modify state rather than just returning something) and has immutable variables. Imperative programming, on the other hand, makes frequent use of side effects, and happily alters variables.
If you’ve ever written any SQL, that’s declarative: you describe the result you want (a certain selection of records), and the code chooses how it returns that result. In general, many languages can be written in either an imperative or a declarative style, although some are much more inclined one way than the other. C, for example, is highly imperative; Haskell is highly declarative (as are other functional languages).
If your main experience is in imperative programming, the declarative approach can feel awkward. Here’s a Python example of doing the same thing in two different styles. You can try it out in a browser at www.skulpt.org.
# Declarative fours = [x for x in range(100) if x%4 == 0 ] print fours # Imperative fours = [] for i in range(100): if i%4 == 0: fours.append(i) print fours
(With thanks to Mark Rushakoff.) The first one says what you want – numbers which are multiples of 4 (% is the modulo operator) – and the implementation is up to the machine. The second one describes exactly how to construct the required array.
Functional programming
Functional programming is declarative; functional languages construct and evaluate functions and treat data as unchangeable. So you can’t alter data in-place; instead you have to apply a function to one data item and store the result in another data item. It’s based
on lambda calculus, which is a theoretical mathematical framework for describing functions. It will also use higher-order functions (functions that operate on functions) where an imperative language might use a loop.
The avoidance of side-effects makes programs easier to verify and to parallelise. However, some things (I/O being one notable example) do seem best suited to some kind of state approach. Functional languages will ‘fake’ this in various ways: Haskell uses monads; other languages use data structures to represent the current state of a thing.
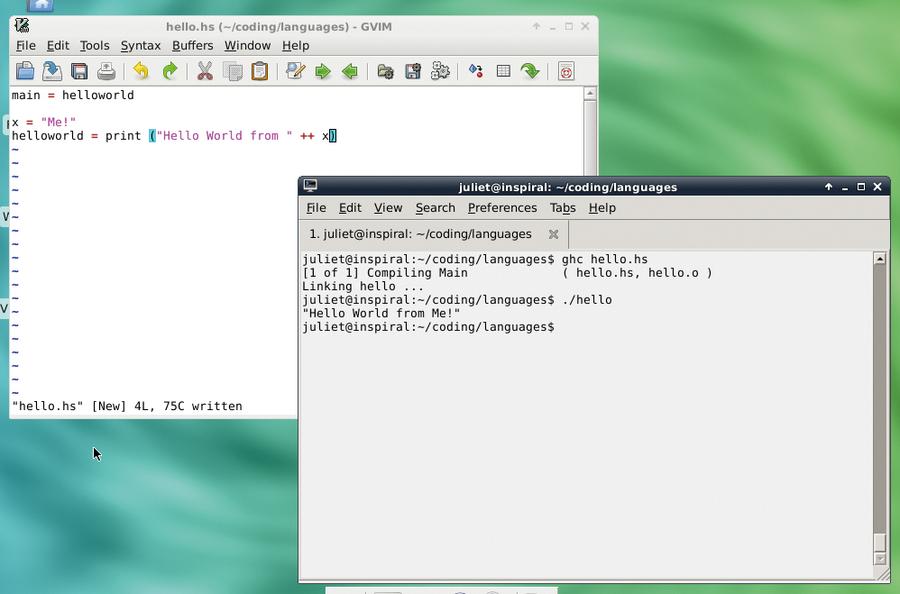
Lisp was the earliest functional-type language; it was followed by APL (see above) and ML, which has various offshoots. Probably the best known modern functional language is Haskell. There’s a Haskell example above; here’s another one (save as hello.hs):
main = helloworld x = “Me!” helloworld = print (“Hello World from “ ++ x)
Compile and run it with ghc hello.hs; ./hello. helloworld is a function, and x is a variable, but they can both be defined in the same way. main is the main program control structure (what runs when you execute the compiled file). There’s lots more information and tutorials on the Haskell web page.
Haskell is a functional, rather than a declarative language.
Structured programming
Structured programming argues that programs are composed of three control structures:
Sequence A set of statements or subroutines ordered in a particular sequence.
Selection A statement or statements executed based on the program state (eg if/then structures).
Iteration A statement executed until a certain condition is achieved (eg while, for, do/until).
Blocks and subroutines group statements together. The structured program theorem states that these, when combined, are sufficient to describe any computable function.
Non-structured programming simply has a sequence of commands, although usually these are labelled so that execution can jump to that point. Loops, branches, and jumps exist, and sometimes basic subroutines.
Today, all high-level languages have some form of programming structure (including older languages like Fortran, COBOL, and BASIC), and structured coding is the norm. But early programmers were accustomed to machine code or assembly language, which had only an ordered sequence of commands. A single statement in a high-level language will be spread over multiple statements in assembler. Assembly language coders were skilled at manipulating code in complex and highly efficient ways and it seemed far from obvious that all of this was even conceivably structurable. COBOL was notoriously unstructured and made extensive use of GO TO statements. Edsger Dijkstra’s letter Go To Statement Considered Harmful is probably best-known contribution to the debate.
Structured programming at its most basic means writing code that looks like this:
$a = 3; $pi = 3.14; sub area($_) { return $_[0] * $pi * $pi; } print area($a);
instead of code that looks like this:
print 3 * 3.14^2;
The second might be shorter, but it is less reusable and less maintainable.
Procedural programming is derived from structured programming, and is based on the idea of procedures (or methods, or functions), consisting of a series of steps. It is often contrasted with object-oriented programming (OOP).
Object-oriented programming
It’s nearly impossible these days not to have encountered OOP (whether or not you like it). Many modern languages are multi-paradigm and support OO alongside a more imperative style (eg Perl, PHP, Python). Java, in contrast, is exclusively OO.
The basic OOP idea is to fold both code and data into objects with behaviour (code) and state (data). Code is executed by creating an object and causing it to behave in a particular way. So to add X and Y, you would pass X into Y’s “add” method (Y.add(X)).
Objects can inherit methods and data from one another, so OO languages have a class (object) hierarchy. OOP encourages modular programming (though non-OO languages can also support modules), intended to simplify code reuse, by bundling together objects and everything associated with them.
Some of the advantages claimed for OOP are:
Improved code reusability; great for modules and code libraries.
Interfaces and encapsulation make it easier to use others’ code; you need only understand the interface, not the details of the code.
Encapsulation makes it easy to hide values that shouldn’t be changed.
Improved code organisation and simpler syntax.
Forces better advance planning, and is easier to maintain afterwards.
There are also, of course, disadvantages:
OO programs tend to be large. This is less of a problem on modern machines with lots of memory and hard drive space.
Programs are often slower, although again with modern machine resources this is less important.
More effort required up-front, which some may consider wasteful. The larger the project, the less true this is, but for a small project the effort may be overkill.
Lots of code boilerplate. (This is less hassle with a decent IDE.)
Both advantages and disadvantages are true; which way they balance will depend on the project and the people working on it.
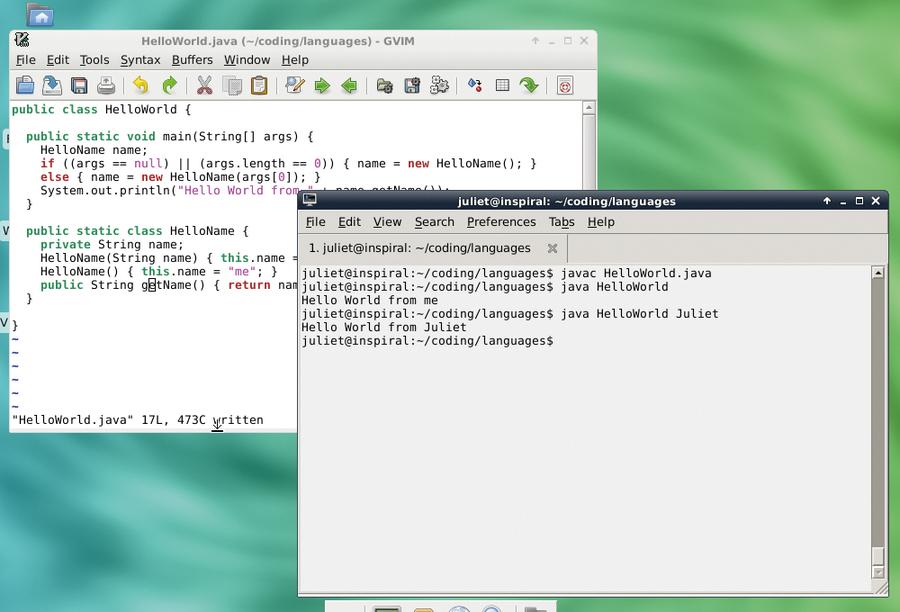
Here’s a brief Java example (save as HelloWorld.java):
public class HelloWorld { public static void main(String[] args) { HelloName name; if ((args == null) || (args.length == 0)) { name = new HelloName(); } else { name = new HelloName(args[0]); } System.out.println(“Hello World from “ + HelloName.getName()); } private static class HelloName { private String name; HelloName() { this.name = “me”; } HelloName(String name) { this.name = name; } public String getName() { return name; } } }
This is deliberately a little verbose to demonstrate objects. The HelloName object stores a name; you could easily extend it to store more data. The HelloWorld class creates the new object, then uses the getName() method to retrieve the string. Compile it with javac HelloWorld.java and run it with java HelloWorld NAME.
Our HelloName example in Java runs both with and without a name provided on the command line.
More out there…
There are a bunch of types and areas of programming language I haven’t been able to cover here, including systems programming, logic programming, reflection programming; ideas around modularity, security, concurrency, and other aspects of modern computing also inform current thinking.
Language development continues at a fair old clip, to the point that any attempt to list languages available as I write would probably be out of date by the time we go to print. And all of them – all the languages, all the paradigms, all the tweaks and mechanisms and constructs – have their places where they’re useful and their places where they don’t fit. One of the joys of programming is just how many options there are out there to explore.
Interpreted vs compiled
In the very early days, programs were neither interpreted nor compiled. Instead, programmers wrote machine code, which ran directly on the hardware. Once languages began to be developed, the distinction between compiled and interpreted developed alongside them.
Broadly speaking, a compiled language is one in which the instructions written by the programmer are translated (by the compiler) into machine code all at one go. The compiled program can then be run on the machine. Parse everything, then run it.
Interpreted languages, in contrast, are read at runtime by another program, an interpreter, which then translates each instruction, one at a time, into machine code. So parsing and execution happen at the same time. Parse a statement, run it, parse the next statement, and so on.
In modern languages, the distinction can be quite blurry. Some modern compilers can parse and execute in memory, so although the steps are distinct, the programmer issues only one command. Other languages compile to virtual machine bytecode, which is another step (or more!) away from the metal. Ultimately, any program has to be translated into machine code; the question is how that process occurs and which steps occur in what order.
Interpreted and compiled languages both have their advantages and disadvantages; as ever, it’s about using the best tool for the job.
Related Posts

About The Author
Juliet Kemp
Juliet is a scary polymath, and is the author of O’Reilly’s Linux System Administration Recipes. http://julietkemp.com